
gephi中如何计算网络的平均聚类系数 gephi聚类布局
今天给各位分享gephi中如何计算网络的平均聚类系数的知识,其中也会对gephi聚类布局进行解释,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
浅谈文本分析分词及关系图
在文本分析中,我们需要对其文本进行分词,并对这些分词统计分析,基于 python , jieba 是很受欢迎的一种分词库,而后对分词之间的关系,当然Python Matplotlib 基于networkx画关系网络图也是可以的,但是这里我们将借助 Gephi 来制作,这个软件容易上手,这里我们并对其中个别方法进行解释。
jieba库是Python中一个重要的第三方中文分词函数库,能够将一段中文文本分隔成中文词语序列。
jieba库分词所用的原理就是把分词的内容与分词的中文词库进行对比,通过图结构和动态规划方法找到最大概率的词组。
支持四种分词模式:
四种模式分隔举例:
结果:
由上我们可以发现,我们想要把生态环境、污水处理、有限公司都分开,精确模式和Paddle模式,未分开,全模式和搜索引擎模式虽分开了,但却也含有未分的词组。所以这里我们可以采用自定义词典,使用load_userdict(),不过注意的是需要给自定义词做词频,否则自定义词典不起作用,因为,当自定义词词频低于默认词典的词频时,它还是采用默认分词,所以我们设定词频大于默认词词频时,就会采用自定义词典的词分词。
具体怎么设置自定义词典的词频数,还没有具体的公式,越大当然概率越大,只要超过默认词典即可,但也不宜过大。 默认词典
自定义词典
其中 user_dict 定义如下:
jieba简单介绍及使用介绍到这里,更深层理论及使用可学习这个地址: jieba-github参考
在 图论 中, 集聚系数 (也称 群聚系数 、 集群系数 )是用来描述一个 图 中的 顶点 之间结集成团的程度的系数。具体来说,是一个点的邻接点之间相互连接的程度。例如生活社交网络中,你的朋友之间相互认识的程度【 基于复杂网络理论的代谢网络结构研究进展 】。有证据表明,在各类反映真实世界的网络结构,特别是 社交网络 结构中,各个结点之间倾向于形成密度相对较高的网群【 TRANSITIVITY IN STRUCTURAL MODELS OF SMALL GROUPS 、 Collective dynamics of 'small-world' networks 】。也就是说,相对于在两个节点之间随机连接而得到的网络,真实世界网络的集聚系数更高。
假设图中有一部分点是两两相连的,那么可以找出很多个“三角形”,其对应的三点两两相连,称为闭三点组。除此以外还有开三点组,也就是之间连有两条边的三点(缺一条边的三角形)。
Clustering coefficient 的定义有两种; 全局 的和 局部 的。
全局的算法:
局部的算法:
平均系数:
下面即分析其系数求解:
接下来我们就以一个实例来分析聚类系数应用,这里我们用到的工具是 Gephi ,数据也是使用其内置的数据。
在上面分析中,我们提到节点大小,代表自身权重,但是有时由于我们的节点范围导致有些需要辨别的节点不易分析,这时我们可以考虑从颜色入手,即权重从小到大以颜色的变化老判定,当然也可以用同一种颜色通过渐变来判定,这里我是使用了三种颜色变化范围来分析。如下图选择及展示:
由上图,从颜色上我们选择了红黄蓝的依次变化情况,右图我们从节点大小加上颜色更方便判定节点自身的权重了,即自身出现次数越多颜色越靠近蓝色,反之靠近红色。
由上俩个图的变化可察觉出它们的布局分布是一样的,那它是什么原因呢?
如图结构可分析形成聚合的簇团,是相互之间弹簧吸引的强烈的,也就是说关系比较密切些。
在数据中,我们关系图是由节点和边组成,上面都简要分析了节点的处理,那么边怎么分析呢?其实边由图中是可以以线的粗细来判断俩个词之间的关系,即出现的次数。如下图:
由于次数范围太广,我们把它们转化成0--1之间的范围,以最高权重为1,其它数据以此为基准做转化。
即为所转化后的占比值, 为每个权重值, 为最大权重值
jieba-github参考
Clustering coefficient
ForceAtlas2, A Continuous Graph Layout Algorithm for Handy Network Visualization
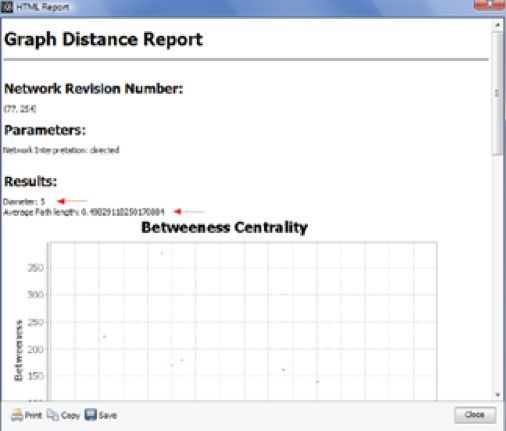
想要计算复杂网络的平均最短距离、平均度、平均聚类系数等值,可以用什么软件啊,还是要在matlab上编程?
如果是一般的度量指标,比如你说的,一般的网络分析软件都有,比如gephi
如果是自己定义的指标,自己写代码吧
网络数据统计分析笔记||网络图的数学模型
前情回顾:
Gephi网络图极简教程
Network在单细胞转录组数据分析中的应用
Gephi网络图极简教程
Network在单细胞转录组数据分析中的应用
网络数据统计分析笔记|| 为什么研究网络
网络数据统计分析笔记|| 操作网络数据
网络数据统计分析笔记|| 网络数据可视化
网络数据统计分析笔记|| 网络数据的描述性分析
在前面的章节中我们了解到网络图的构建,可视化,以及网络结构的特征化描述。从本章开始,我们将进入网络图建模的主题,在网络数据分析中构建与使用模型。本章主要介绍几种常见的数学模型,就像我们在学统计建模的时候,先要学习几个常见的分布模型一样。关于统计建模的一般性描述见 环境与生态统计:R语言应用 。
所谓的网络图模型是指:
其中 是所有可能的图的集合, 是 上的一个概率分布, 是参数构成的向量,该向量的所有可能取值为 。
在随机图模型(Random graphs)中,我们模仿这样的一个环境,假如一个团体中有很多的个体,之后两个人随机的认识并且成为朋友,那么随着时间的推移,这个团体会变成什么样子呢?或者说这个以人为节点,边代表好友关系的网络会是什么样子的呢?
正式地讲,随机图模型通常是指一个给定了集合 及其上的均匀概率分布 的模型。其重要作用和完备性就像统计建模中的均匀分布一样。
比较常见的随机网路模型是Erdos-Renyi model,可以通过 sample_gnp 来构建。
查看图中组件和团的情况
可以看到我们生成的随机图不是连通的,有一个 巨型组件。
经典随机网络的性质包括:平均度与期望值比较接近,度分布均匀,节点对之间最短路径上的节点相对较少等。
广义随机图模型是经典随机图模型的一般化,具体地:
在Erdos-Renyi模型之外,最常选择的特征是固定度序列。假设对于节点数为8,一半节点的度为2,另4个节点的度为3,从满足条件的图集合中均匀抽取两个。
可见两个图并非同构。
我们可以从构建一个与已知图序列相同的图:
模拟图直径减少一半,之前的聚类也减少了。
随机图模型为我们描述了在不受任何条件控制的条件下的图,可理解为数学模型的背景模型,但是现实世界里的图往往是由特定结构的。基于机制的网络图模型 把我们带入了现实世界。其中最著名的需要所小世界模型了。
小世界模型最经典的特征是既具有规则网络的高聚集性,又具有类似随机网络的小直径。相较随机图模型,小世界模型能够更好地反映真实网络的情况。就像我们人类社会一样,人以群分,六度分隔。
例如在写本笔记的时候:
媒体经常提到COVID-19呼吸道疾病的病例和死亡人数呈“指数”增长,但这些数字暗示了其他东西,一个可能具有幂律属性的“小世界”网络。这将大大不同于疾病的指数增长路径。
在介绍随机网络时提到,随机网络无法解释真实网络中存在的一些情况:局部集聚(较高的集聚系数)和三元闭合(朋友的朋友是朋友)。从网络结构来看,随机网络与真实网络的一大差异便是过低的集聚系数,所以在随机网络模型基础上进行改进时,需要要着重考虑的便是——如何在保留小网络直径这一特点的同时提高集聚系数,使得构建的模型能够对网络局部结构进行更好的刻画。
小世界的性质:
优先连接”(preferential attachment)指的是进入一个网络的新节点倾向于与节点度高的节点相连接。反过来说,一个节点如果已经接受了很多连接,那么它就越容易被新来的节点所连接。
优先连接现象最早是在1925年,由英国统计学家George Udny Yule研究的。后来科学计量之父Derek J. de Solla Price在1976年也研究了这一现象,并把它叫做积累优势(cumulative advantage)。不过,描述优先连接最著名的模型是Albert-Laszlo Barabasi和Reka Albert提出的,所以也被叫做Barabási–Albert模型或BA模型。它的基本形式非常简明:一个新的节点i连接到网络里某个已有节点j的概率,就是节点j的度占全部已有节点的度之和的比重。
BA模型的节点度符合幂律分布,生成的是一个无标度网络(scale-free network)。
网络无标度性的形成有两个基本的要素:一是网络生长,也就是新的节点加入网络的过程;二是网络生长过程当中的优先连接。
ba网络的性质
如开头所言,随机网络作为网络的背景,它经常用来评估网络特征的显著性:即,待观测的网络与随机网络有多大程度的不一样?
假设我们有一个来自某种观测的图,此处称为 ,而我们对某些结构特征感兴趣,不妨称为 。在很多情况下,自然会考虑 是否是显著的,即在某种意义上是不寻常的和超预期的。这一过程很像我们的统计推断过程 统计推断概述 。
生成参考分布
而真实的我们数据的社团数是:
可以说是很显著的了。这时,你要问为什么?
评估小世界性的一种经典方法是:针对待观测网络以及可能观测到的/经过适当修饰的经典随机图,比较两者聚类系数和平均(最短)路径的长度。如果出现小世界性:
评估有向图的小世界性:
0.5501073 0.2548 ; 2.148485 1.858 具有一定程度的小世界性质。
有没有大神知道引文网络分析法的具体步骤还有分析工具?
一般来说,引文网络分析的具体步骤如下:
选择研究的学术领域和时间段,并收集相关论文。
对论文进行解析,提取出论文的引文信息。
建立论文之间的引文关系网络。
分析网络中的节点和边,了解论文之间的关系。
对网络进行可视化,通过图形更直观地展示论文之间的关系。
分析论文的影响力,比如计算论文的引用次数、引用深度、引用宽度等。
在总结本文时,我们可以看到,gephi中如何计算网络的平均聚类系数的重要性在当今社会中越来越受到重视。通过本文的探讨,我们了解到了gephi聚类布局的知识。希望本文能够对读者有所帮助,同时也希望大家能够在实践中不断探索和发掘gephi中如何计算网络的平均聚类系数的更多可能性。
本站文章为热心网友投稿,如果您觉得不错欢迎转载,转载请保留链接。网址:http://xzz5.com/z3107

温度传感器类型原理介绍 温度传感器类型原理介绍图片

魔兽世界怀旧服匹瑞诺德王冠在哪里 wow匹瑞诺德王冠

来临之际和来临之前的区别 来临之际还是来临之即
铁件防锈处理工艺 铁件防锈处理工艺流程

欧洲四日游 欧洲四国旅游攻略

被窝是青春的坟墓讲述了什么 被窝是青春的坟墓
99是什么 99是什么服务
手机域名注册多少钱 手机域名注册多少钱一个

hover的用法 hover用法

朔望是什么意思啊 朔朏望晦是什么意思

庄彦江 庄彦江国画大师

摩羯座 摩羯座今日运势查询女

当季水果有哪些12月 1至12月当季水果

藩王是什么意思 藩王的臣子称为藩臣吗

广州国税网上服务大厅 广州国税网上服务大厅官网
mp4转换rmvb格式转换器 mp4格式转换器怎么用?
知识改变生活
